AtCoderで7回目の青を目指すための計画
一応趣味は競技プログラミングということにしているものの、AtCoderのAlgorithm部門では2022-02-05 に青であったのを最後に2年半以上も青に戻ることができていません。
https://atcoder.jp/users/minus9d

最初はそのうち青色に戻るだろうと思っていたものの、もはや適正レートが1400台であることを認めざるを得ません。
この2年半は勉強せず実力テストを受けるのを続けていたようなものなので、レートが上がらないのは当然と言えば当然です。 少しずつ時間もできてきたので、真面目に勉強をやり直してレートを1600に戻すことを画策中です。
自分の弱点で思いつくものを書き出してみます。
- 緑パフォーマンスをしばしばとってしまう
- ABCで2000~3000人以上が解いているような緑diff, 水diffの問題が解けず大コケしてレートが-40, -50となることがしばしばあります
- 知識の穴がかなりあるように思います
- 有名問題の解法や典型を把握できていない
- LIS (Longest Increasing Subsequence) をDPで解く、と言われても、ピンとこなかったりします
- 遅延セグ木、全方位木DPなど、ここ数年で出題頻度が上がり典型化したと思われるテクニックや解法も十分フォローできていません
- 解法テクニックが脳のキャッシュに乗っていない
- 解説を見ると見たことがある解法であっても、コンテスト中は完全に思いつけていないことが多いです
- 考察 and/or 実装が遅い
- ABCのC問題くらいまで自分の中ではほとんど詰まらずにできたつもりでも思ったより順位が出ない(1,000位にも入れていない)というパターンが多いです
- 考察と実装のどちらが遅いのかは分かりませんが、おそらく両方。
- 考察:脳の老化で脳のクロックが落ちていることが疑われるので、改善不可能かも?
- 実装:コーディングの練習をすれば改善しそうですが、その時間がなさそう。スニペットやマクロを整備するなどの地味な作業は効きそう(本質ではないが)
- 実装でハマる
- 昔からですが、解法は見えていても実装でハマって解ききれないパターンが多いです
- テンプレ不足
この中でもっとも致命的なのは「緑パフォーマンスをしばしばとってしまう」なので、まずは難易度の低い問題を確実に解けるようにすることを目指していきます。
ここまでにやったことは以下です。
- Cosense (旧Scrapbox) にメモ用ページを開設
- https://scrapbox.io/minus9d-prog-contest にメモ用ページを開設しました
- 勉強したことをブログにまとめるとなると心理的障壁が高いですが、このサイトでは誤りを気にせず見聞きしたことを書いていくことにしました(たまたま検索で引っかかった人には申し訳ないですが)。
- 競プロ典型 90 問
- 2021年6月に27番までの簡単な問題のみ解いて放置していたので、再開しました
- 本当は実際に考えてコーディングしてだめなら解説を見る、とすべきだとは思いますが、数分考えたらすぐ解説を見るスタイルを試しています
- ★7の問題はかなり難しいですが一応解説は見て、キーワードだけでも把握することをしています
- 問題文を見たら解法がすぐに思いつくようになるまで何周かしてみる予定です
- 取り組むべき資料のリスト化
- 勉強する価値が高そうな資料を見つけたら随時 https://scrapbox.io/minus9d-prog-contest/%E7%AB%B6%E6%8A%80%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0%E5%8B%89%E5%BC%B7%E3%83%AA%E3%82%B9%E3%83%88 に追加し、次に勉強すべきアイテムを適宜追加しています。
本当は今年中に青復帰と言いたいところですが、現実的にはかなり難しいと思うので、年末時点でレート1500を目標にしておきます。
消耗品の本体と詰め替えの価格差を調べる
洗剤等の消耗品は本体より詰め替え用のほうが得だと思いがちだけど、実はそうではないことが経験則としてあります。 2024年8月2日現在、ヨドバシカメラの値段はどうなっているかを調べました。 ヨドバシカメラの値段はよく変動するのであくまで目安です。
太字 がもっともお得な商品です。
NANOX one スタンダード
| 品物 | 容量 (g) | 価格 | g当たりの価格 |
|---|---|---|---|
| 本体 | 380 | 348 | 0.916 |
| 本体大 | 640 | 557 | 0.870 |
| つめかえ用特大 | 820 | 764 | 0.932 |
| つめかえ用超特大 | 1160 | 1030 | 0.888 |
| つめかえ用ウルトラジャンボ | 1530 | 1460 | 0.954 |
| つめかえ用業務用 | 4000 | 3720 | 0.930 |
僅差ですが、本体がもっともお得でした。つめかえ用は超特大がお得で、それ以外はかなり割高です。
フレアフレグランス フローラルスウィートの香り
| 品物 | 容量 (ml) | 価格 | ml当たりの価格 |
|---|---|---|---|
| 本体 | 270 | 309 | 1.144 |
| 詰め替え用 | 380 | 315 | 0.829 |
| 詰め替え用 2.5倍 | 950 | 666 | 0.701 |
| 詰め替え用 4.7倍 | 1800 | 1240 | 0.689 |
以前は本体のほうがお得だった記憶がありますが、今調べると順当につめかえ用がもっともお得でした。
エマール アロマティックブーケの香り
| 品物 | 容量 (ml) | 価格 | ml当たりの価格 |
|---|---|---|---|
| 本体 | 460 | 357 | 0.776 |
| 詰め替え | 360 | 273 | 0.758 |
| 詰め替え | 810 | 542 | 0.669 |
これも順当につめかえ用がもっともお得でした。
キュキュット
| 品物 | 容量 (ml) | 価格 | ml当たりの価格 |
|---|---|---|---|
| 本体 | 220 | 208 | 0.945 |
| 詰め替え | 370 | 250 | 0.676 |
| 詰め替え | 700 | 430 | 0.614 |
| 詰め替え | 1250 | 683 | 0.546 |
これも順当につめかえ用がもっともお得でした。
キレイキレイ泡ハンドソープ シトラスフルーティの香り
| 品物 | 容量 (ml) | 価格 | ml当たりの価格 |
|---|---|---|---|
| 本体 | 250 | 323 | 1.292 |
| 本体大型サイズ | 500 | 445 | 0.890 |
| つめかえ用 2.2個分 | 450 | 377 | 0.838 |
| つめかえ用 4個分 | 800 | 542 | 0.678 |
順当につめかえ用がもっともお得でした。キュキュットやキレイキレイ泡は両方本体の価格が高めです。 ポンプなどのギミックがあると本体の値段が高いのかもしれません。
WSL2 + Ubuntu 22.04 のGUIアプリで日本語変換できるようにする
WSL2 + Ubuntu 22.04 でgeditなどのGUIアプリを使用する際、日本語入力できるようにしました。現時点でgeditでは日本語入力できていますがemacsではできていません。
試行錯誤したので書き漏らしがあるかもしれません。
基本の設定
基本、Windows Subsystem for Linuxガイド 第24回 WSLgの日本語入力を設定する を参考にしましたが、ほかのサイトも同時並行で参照していたので一部異なる方法をとっています。
- sudo apt -y install language-pack-ja
- (スキップ) sudo localectl set-locale ja_JP.UTF-8
- (スキップ) Windows側のフォントをLinux GUIアプリケーションで利用できるように設定
- これの代わりに
sudo apt install fonts-noto-cjk fonts-noto-color-emoji fonts-noto-monoでフォントを入れました。 - フォントを入れることで、emacsで日本語を含むファイルを開いたときに文字が豆腐になる現象は防げるようになります。
- これの代わりに
- sudo apt install fcitx5-mozc -y
- .zprofileに以下を記載
- zshユーザなので.profileのかわりに.zprofileとしました
export GTK_IM_MODULE=fcitx5 export QT_IM_MODULE=fcitx5 export XMODIFIERS=@im=fcitx5 export INPUT_METHOD=fcitx5 export DefaultIMModule=fcitx5 if [ $SHLVL = 1 ] ; then (fcitx5 --disable=wayland -d --verbose '*'=0 &) fi
ps aux | grep fcitx5でプロセスが立ち上がってるか確認fcitx5-configtool &で設定ツールを起動し、 -「入力メソッド」タブで、「日本語 (OADG 109A)」と「Mozc」を左側に並べる- 「グローバルオプション」タブで、「入力メソッドの切り替え」をお好みで設定
emacs用の設定
半角ボタンを押すと日本語入力になるようにfcitx5-configtoolで設定したつもりでも、emacsで半角ボタンを押すと<zenkaku-hankaku> is undefinedと言われてうまくいきません。
とりあえず以下の方法をとることでC-\によりmozcが立ち上がるようにはできました。
Emacs日本語入力をMozcに変更する - minisoba blog を参考にしました。
;; C-\でmozc ;; https://minisoba.com/entry/2022/06/05/232006 ;; sudo apt install emacs-mozc emacs-mozc-bin が必要 (load-file "/usr/share/emacs/site-lisp/emacs-mozc/mozc.el") (setq default-input-method "japanese-mozc")
catコマンドの改善版 batコマンドについて調べた
Linuxのcatコマンドのクローンである batコマンドというのを教えてもらいました。自分で試して便利だと思ったことをまとめます。
特徴
- 言語に応じた色分けをして表示してくれる。
- Git管理されているファイルを指定すると、diffの有無を表示してくれる。
Ubuntu 22.04 でのインストール
$ sudo apt install bat
で入りました。ただしUbuntuの場合、名前衝突を避けるために /bin/batcat というコマンドが入ってしまいます。
以下、alias設定によりbatと打てばbatcatが呼ばれるようにしたことを前提とします。
基本的な使い方
bat <ファイル名>とするだけです。以下はOptunaのpyproject.tomlをbatコマンドで閲覧したときの例です。

1画面に収まらない長さのファイルを開いたときは、デフォルトではページャーとしてlessが呼ばれます。よって、行の移動などの操作方法はlessに準じます。 代表的な操作の例を以下に記します。
| 内容 | コマンド |
|---|---|
| ヘルプ表示 | h |
| 1行下へ | j (カーソルなど他の方法もあり) |
| 1行上へ | k (カーソルなど他の方法もあり) |
| 5行下へ | 5j (カーソルなど他の方法もあり) |
| 5行上へ | 5k (カーソルなど他の方法もあり) |
| 文字列の前方検索 | / |
| 文字列の後方検索 | ? |
| 30行目に移動 | 30g |
| ファイルの冒頭から20%地点に移動 | 20p| |
| ファイル先頭に移動 | g または < |
| ファイル末尾に移動 | G または > |
manコマンドのカラー化
export MANPAGER="sh -c 'col -bx | bat -l man -p'" を設定するとmanコマンドがカラーで閲覧できるようになります。以下はman 2 select した例です。

左側の行番号を省きたいとき
bat --plain <ファイル名> or bat -p <ファイル名>
2023年の振り返り
2022年の振り返り に引き続き、2023年の簡単な振り返りです。2月も半ばになってしまいましたが…。
競技プログラミング
2023年はAtCoder Algorithmのratedに18回出場。レートは2022年末の1585から2023年末の1443に激減しました。
2023年もほとんど出場できていない感覚でしたが、意外にも18回も出場していました。 2023年は、コンテストに出る以外のことはほぼなにもできていなかったという点で2022年とほぼ同じですが、 2022年に比べてレートは急激に低下していて、ついに実力の維持すらままならなくなっている状況です。
2024年も状況が変わるようになるとは思えませんが、少しでも実力を改善するためにやりたいと思っていること:
- 通勤時間に問題と解説を見る
- 本当は心行くまで問題の解法を考えてから解説を見たいところですが、そんな時間はありません。理想からは外れますが、「問題を見る→すぐ解説を見る」という方法でも競プロの感覚を取り戻せないかというのを試したいです。
- AtCoder Library (ACL) を一通り使う
- 実はまだACLを導入できていません。できることの把握と、ACL contest 1とACL contest 2のACをやりたいです。
下は2024年1月7日に取得したAtCoderとAtcoder Problemsのスクリーンショットです。

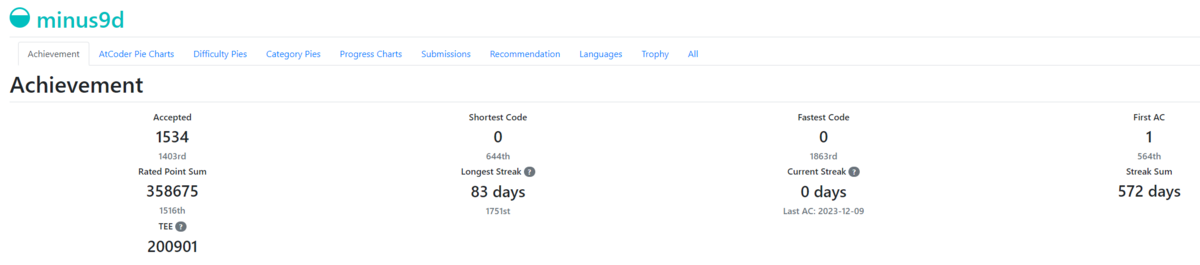
ブログ
月に一本記事を書くストリークは一応保てましたが、今年も簡単な記事ばかりでした。せっかく良いPCを新調したので新しいことを勉強して記事にまとめたくはあるのですが…
そして2024年1月は記事が書けず、ついにストリークは途切れてしまいました… 今年は無理に月に一本記事を書くことには固執せず何か意味のある記事を書けるように努力したいです。
勉強
2022年は家事をしながらYouTubeで学習コンテンツを流し見、というのをやっていたのですが、2023年はそれもできませんでした。
難しいこと・未知のことを勉強するにはまとまった時間集中して取り組みたいのですが、そのような貴重な時間はほぼとれず。 仮に取れたとしても勉強以外のことに充てたくなってしまい、まったくといっていいほど前進のない一年でした。 今年は隙間時間を使って以下に少しでも勉強するかを追求したいです。
また、LLMや生成モデルの流行に全然ついていけていないのがまずいです。中身の理解をしたりライブラリを触ったりという時間は取れなくても、 せめて一ユーザーとしての最低限の興味を持ってサービスを利用するくらいのことはしておきたいです。
ffmpegに関するメモ
動画を60秒おきに分割(再エンコードなし)
ffmpeg -i input.mp4 -c copy -segment_time 60 -f segment -reset_timestamps 1 output_%02d.mp4
参考 - windows 7 - How to split videos with FFmpeg and -segment_times option? - Super User
動画を32秒目、98秒目で分割(再エンコードなし)
この例の場合、3つの動画に分割されて出力されます。
ffmpeg -i input.mp4 -c copy -f segment -segment_times 32,98 -reset_timestamps 1 output_%02d.mp4
Plotlyに関するメモ
最近グラフの可視化によく使っているPlotlyに関するちょっとしたメモです。
plotly.expressとplotly.graph_objects
plotlyのスクリプト例を検索すると、
import plotly.express as px
しているものと
import plotly.graph_objects as go
しているものの両方があることがわかります。
plotly.expressの方は少ない行数でサクッとグラフを作るのに向いていて、特にPandasのDataFrameとの親和性が高いです。 ただし高水準APIのため、ちょっと難しいこと(例えば二つのサブプロットを並べるとか)をしようとするとすぐ壁に当たります。
逆にplotly.graph_objectsは低水準APIのため、行数は多くなりますが、plotly.expressよりも痒い所に手が届きやすいです。 個人的には初めからplotly.graph_objectsを使用するようにしています。
go.Scatter()よりgo.Scattergl()
散布図を描くサンプルを検索するとgo.Scatter()が使われていることが多いですが、代わりにgo.Scattergl()を用いる方がブラウザでさくさく動くので、
基本的にgo.Scattergl()を使った方がよいはずです。(少なくともそれなりのGPUを積んでいる環境では。)
公式ページの "What About Dash?" は無視してよい
公式ページのチュートリアル、例えば ここを開くと、高確率で最後に "What About Dash?" という節があります。 これはDashというGUIツールの宣伝で、これはこれで便利なツールではありますが、基本的に無視してOKです。